AWS ECS Cost Optimization: Migrate Fargate to EC2
Image by Arief JR
Today I will share my experience about how to cost optimize with AWS ECS and EC2, and use Terraform to automate the process. AWS ECS is a powerful service for container orchestration, AWS ECS provide two type of instance, EC2 and Fargate. The fargate is a serverless service, currently the company where i working is using fargate.
AWS ECS with fargate is very good option for have large service (microservice) without provision, configure, or manage the underlying EC2 instance.
Currently the traffic is small not high, so i use EC2 instance for cost optimization. with EC2 instance, we can use spot instance to minimize the cost and also enable vpc trunking so 1 instance can handle multiple service. You can refer of the documentation if you want to know more about vpc trunking and supported instance type in here VPC Trunking Supported Instances.
Comparison between AWS ECS with EC2 and AWS ECS with Fargate
| Feature | AWS ECS with EC2 | AWS ECS with Fargate |
|---|---|---|
| Infrastructure | Fully managed by AWS (serverless compute engine for containers) | User-managed EC2 instances |
| Management | Very low operational overhead | Higher operational overhead (managing OS, ECS agent, patching, etc.) |
| Control | Task-level control only, limited flexibility | Full instance-level control, high flexibility |
| Pricing Model | Per vCPU/memory per second (pay-as-you-go for resources consumed) | Per instance hour (plus EBS, data transfer, even for idle capacity) |
| Cost | Generally higher per hour, but no idle cost | Potentially lower for high utilization/commitments (e.g., with Reserved Instances/Spot Instances) |
| Scaling | Automatic scaling at the task level | Automatic scaling at the instance level (via Auto Scaling Group) |
| Instance Types | Predefined Fargate configurations only | Choose from all available EC2 instance types |
| GPU Support | No | Yes |
| Host Access | No direct access to the underlying host OS | Yes, direct access to the EC2 instance |
| Use Cases | Bursty or unpredictable workloads, microservices, development/testing environments | Consistent workloads, workloads requiring specific instance types or specialized hardware (e.g., GPUs), fine-grained control, custom requirements |
Simulation Cost betweenn AWS ECS with EC2 and AWS ECS with Fargate
For example the task have 45 and all service running on linux x86_64:
ECS With Fargate Spot
The cost calculation is as follows:
Unit Price vCPU 0.015168 USD/vCPU/hour Memory 0.001659 USD/GB/hour Storage 0.000133 USD/GB/month Monthly CPU Charges Total vCPU charges = (# of Tasks) x (# vCPUs) x (price per CPU-second) x (CPU duration per day by second) x (# of days) » Because the duration is 24 hours, so i calculate the duration perhour. The total monthly charges of cpu = 45 * 2 * 0.015168 * 24 * 30 = 982.886 USD
Monthly Memory Charges Total memory charges = (# of Tasks) x (# GB of memory) x (price per GB-second) x (memory duration per day by second) x (# of days) » Because the duration is 24 hours, so i calculate the duration perhour. The total monthly charges of memory = 45 * 4 * 0.001659 * 24 * 30 = 215.006 USD
Monthly Storage Charges Total storage charges = (# of Tasks) x (# GB of storage) x (price per GB-second) x (storage duration per day by second) x (# of days) » Because the duration is 24 hours, so i calculate the duration perhour. The total monthly charges of storage = 45 * 20 * 0.000133 * 24 * 30 = 86.184 USD
The total monthly charges = 982.886 + 215.006 + 86.184 = 1.284 USD
ECS With EC2 Spot
Assume the AWS ECS has enabled VPC Trunking, for example i will use 4 m5.xlarge instance type with spot instance. The cost calculation is as follows:
Unit Price Instance 0.0829 USD/hour Storage 0.096 USD/GB/month Monthly Instance Charges 4 instances x 0.24 USD On Demand hourly cost x 730 hours in a month = 700.800000 USD 700.800000 USD - (700.800000 USD x 0.72) = 196.224000 USD Spot instances (monthly): 196.224000 USD 2,920 total EC2 hours / 730 hours in a month = 4.00 instance months 100 GB x 4.00 instance months x 0.096 USD = 38.40 USD (EBS Storage Cost) EBS Storage Cost: 38.40 USD Amazon Elastic Block Store (EBS) total cost (monthly): 38.40 USD
The total monthly charges = 196.224000 + 38.40 = 234.624000 USD
Implementation Overview
For this setup, i’ll configure AWS ECS with an Auto Scaling group using EC2 instances. The infrastructure specifications are as follows: Instance Types:
m5.xlarge (Spot Instance):
1
2
4 vCPUs
16 GB of memory
The Auto Scaling group will be configured to launch a new instance when the current instance count is below the desired capacity. The Auto Scaling group will also be configured to terminate instances when the current instance count is above the desired capacity.
But i will use terraform to create the AutoScaling group and attach to the ECS cluster for capacity provider. Here are a few select examples of Terraform code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
module "ecs" {
source = "../modules/aws-ecs/"
cluster_name = local.name
cluster_configuration = {
execute_command_configuration = {
logging = "OVERRIDE",
kmsKeyId = "arn:aws:kms:{fill your aws region}:xxxxxxxx:key/xxxxxxx-4bb9-xxxxx-xxxxx-xxxxxx"
log_configuration = {
cloud_watch_log_group_name = "/aws/ecs/${local.name}"
}
}
}
default_capacity_provider_use_fargate = false
autoscaling_capacity_providers = {
# Spot instances
prod-env = {
auto_scaling_group_arn = module.autoscaling_prod["prod-env"].autoscaling_group_arn
managed_termination_protection = "ENABLED"
managed_scaling = {
maximum_scaling_step_size = 1
minimum_scaling_step_size = 1
status = "ENABLED"
target_capacity = 100
}
lifecycle = {
create_before_destroy = true
}
default_capacity_provider_strategy = {
base = 1
weight = 100
}
}
}
tags = local.tags
}
module "autoscaling_prod" {
source = "terraform-aws-modules/autoscaling/aws"
version = "~> 6.5"
for_each = {
# Spot instances
prod-env = {
instance_type = "m5.xlarge"
min_size = 0
max_size = 4
desired_capacity = 1
use_mixed_instances_policy = true
}
mixed_instances_policy = {
instances_distribution = {
on_demand_base_capacity = 0
on_demand_percentage_above_base_capacity = 0
spot_allocation_strategy = "price-capacity-optimized"
}
override = [
{
instance_type = "m5.xlarge"
weighted_capacity = "1"
}
]
}
user_data = <<-EOT
#!/bin/bash
cat <<'EOF' >> /etc/ecs/ecs.config
ECS_CLUSTER=${local.name}
ECS_LOGLEVEL=debug
ECS_CONTAINER_INSTANCE_TAGS=${jsonencode(local.tags)}
ECS_ENABLE_TASK_IAM_ROLE=true
ECS_ENABLE_SPOT_INSTANCE_DRAINING=true
EOF
EOT
}
}
name = "${local.name}-${each.key}"
image_id = jsondecode(data.aws_ssm_parameter.ecs_optimized_ami.value)["image_id"]
instance_type = each.value.instance_type
security_groups = [module.ecs_sg.security_group_id]
user_data = base64encode(each.value.user_data)
ignore_desired_capacity_changes = false
create_iam_instance_profile = false
iam_instance_profile_arn = "arn:aws:iam::xxxxxxx:instance-profile/XXXXX"
block_device_mappings = [
{
# Root volume
device_name = "/dev/xvda"
no_device = 0
ebs = {
delete_on_termination = true
encrypted = true
volume_size = 100
volume_type = "gp3"
}
}
]
vpc_zone_identifier = local.subnet_id
health_check_type = "EC2"
min_size = each.value.min_size
max_size = each.value.max_size
desired_capacity = each.value.desired_capacity
health_check_grace_period = 0
create_scaling_policy = false
termination_policies = [
"Default"
]
autoscaling_group_tags = {
AmazonECSManaged = true
}
capacity_rebalance = true
protect_from_scale_in = false
instance_refresh = {
strategy = "Rolling"
preferences = {
checkpoint_delay = 300
checkpoint_percentages = [35, 70, 100]
instance_warmup = 300
min_healthy_percentage = 50
max_healthy_percentage = 100
skip_matching = true
}
triggers = ["tag"]
}
initial_lifecycle_hooks = [
{
name = "ecs-managed-draining-termination-hook"
default_result = "CONTINUE"
heartbeat_timeout = 3600
lifecycle_transition = "autoscaling:EC2_INSTANCE_TERMINATING"
notification_metadata = jsonencode({ "event" = "instance_terminating", "cluster" = local.name, "asg" = "${local.name}-${each.key}" })
}
]
use_mixed_instances_policy = each.value.use_mixed_instances_policy
mixed_instances_policy = each.value.mixed_instances_policy
schedules = each.value.schedules
tags = local.tags_development
}
And change or update the existing task also service, select to use EC2 and choose capacity provider previously created. Select your existing task definition and create a new revision with JSON.
Example a few of task definition:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
{
"family": "{fill the task name, usually should same with container name}",
"containerDefinitions": [
{
"name": "{fill the container name}",
"image": "{fill the container image}",,
"cpu": 0,
"memoryReservation": 256,
"portMappings": [
{
"name": "{fill the container name}",
"containerPort": 3000,
"hostPort": 3000,
"protocol": "tcp",
"appProtocol": "http"
}
],
"essential": true,
"environment": [
........
],
"mountPoints": [],
"volumesFrom": [],
"secrets": [
{
"name": "XXXXXXXX",
"valueFrom": "arn:aws:ssm:{fill your aws region}:{fill your aws account id}:parameter/production/broom-ml-mrp-service/XXXXXXXX"
},
{
"name": "XXXXXXXXXXX",
"valueFrom": "arn:aws:ssm:{fill your aws region}:{fill your aws account id}:parameter/production/broom-ml-mrp-service/XXXXXXXXXXX"
},
{
"name": "XXXXXXXXXXX",
"valueFrom": "arn:aws:ssm:{fill your aws region}:{fill your aws account id}:parameter/xxxxxxxx/production/xxxxx/xxxxx"
}
],
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/{log_group_name what you want}",
"mode": "non-blocking",
"awslogs-create-group": "true",
"max-buffer-size": "25m",
"awslogs-region": "{fill your aws region}",
"awslogs-stream-prefix": "ecs"
}
},
"healthCheck": {
"command": [
"CMD-SHELL",
"curl -f https://localhost:3000/api/v1/health/ready -H 'action_by: 0' || exit 1"
],
"interval": 30,
"timeout": 5,
"retries": 3,
"startPeriod": 90
},
"systemControls": []
}
],
"taskRoleArn": "arn:aws:iam::xxxxxxxxx:role/xxxxxxx",
"executionRoleArn": "arn:aws:iam::xxxxxxxxx:role/xxxxxxxxxx",
"networkMode": "awsvpc",
"volumes": [],
"placementConstraints": [],
"requiresCompatibilities": [
"EC2"
],
"runtimePlatform": {
"cpuArchitecture": "X86_64",
"operatingSystemFamily": "LINUX"
},
"enableFaultInjection": false
}
Then for service, change to use EC2 as capacity provider like this example:
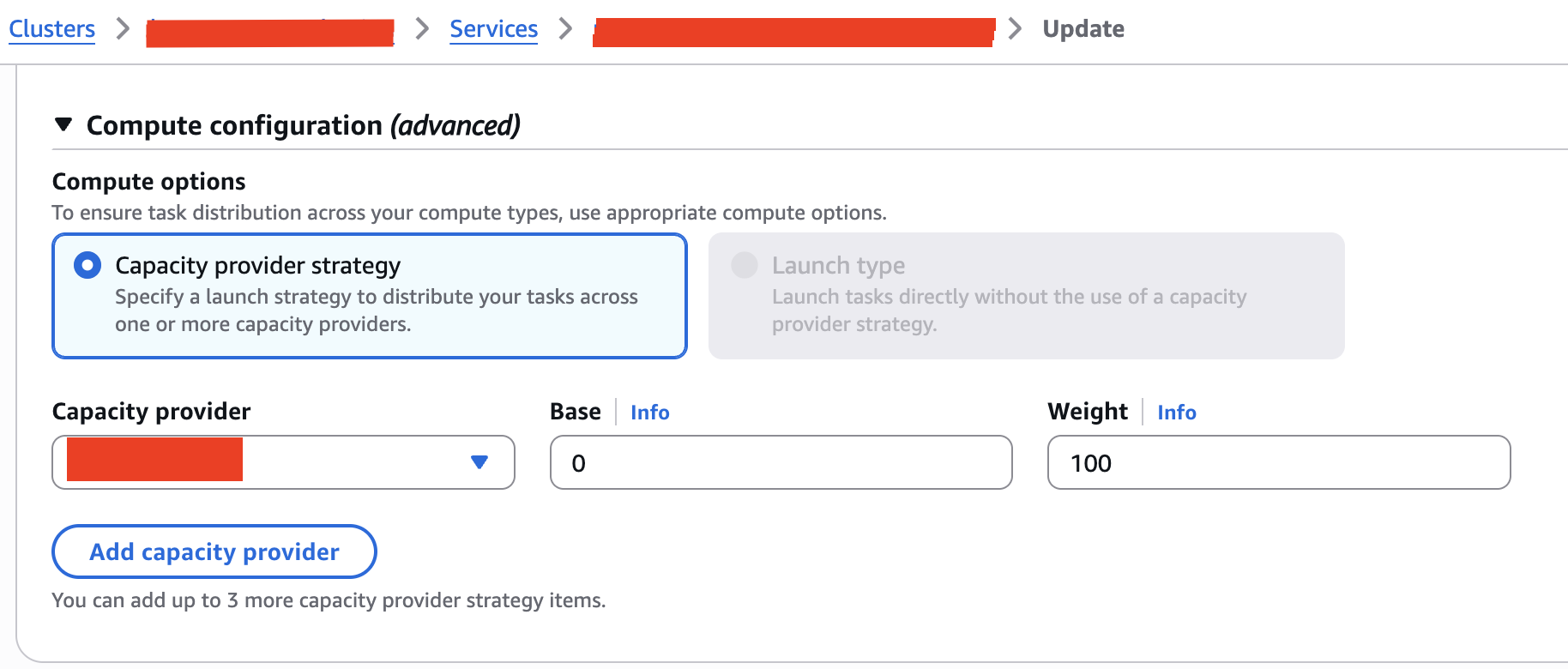
And choose button update, and you can see the service is running on EC2 instance.
Conclusion
- Don’t forget to remove fargate as capacity provider or you can add in terraform line with value
default_capacity_provider_use_fargate = false. - In part
kmsKeyId = "arn:aws:kms:{fill your aws region}:xxxxxxxx:key/xxxxxxx-4bb9-xxxxx-xxxxx-xxxxxx"andiam_instance_profile_arn = "arn:aws:iam::xxxxxxx:instance-profile/XXXXXchange your existing kms key and iam instance profile. If you don’t have iam instance profile, set to true in valuecreate_iam_instance_profile = falsein terraform code that can create new iam instance profile.
Thanks for reading!